
科技改變生活 · 科技引領(lǐng)未來
科技改變生活 · 科技引領(lǐng)未來

近日,全球計(jì)算機(jī)視覺頂會(huì) CVPR 2019 在美國長灘拉開帷幕。北京曠視科技有限公司在 CVPR 2019 的3項(xiàng)挑戰(zhàn)賽中,最終擊敗Facebook、通用動(dòng)力、戴姆勒等國內(nèi)外一線科技巨頭/知名高校,共計(jì)斬獲6項(xiàng)世界冠軍!
本次賽事中,曠視共參加 CVPR 2019 WAD(Workshop on Autonomous Driving)、CVPR 2019 FGVC(Workshop on Fine-Grained Visual Categorization)、CVPR 2019 NTIRE(New Trends in Image Restoration and Enhancement workshop)3項(xiàng)挑戰(zhàn)賽,涵蓋自動(dòng)駕駛、新零售、智能手機(jī)、3D 等眾多領(lǐng)域。

圖:曠視斬獲 CVPR 2019 挑戰(zhàn)賽6項(xiàng)世界冠軍
CVPR 2019 WAD nuScenes 3D Detection Challenge
CVPR 2019 WAD 是自動(dòng)駕駛領(lǐng)域的權(quán)威比賽,其中nuScenes比賽方向是3D detection,旨在通過模型分析3D激光雷達(dá)/相機(jī)數(shù)據(jù),賦予自動(dòng)駕駛汽車偵測物體的能力,保障行駛安全。
nuScenes 是今年自動(dòng)駕駛公司Aptiv發(fā)布的一個(gè)全新數(shù)據(jù)集,除了包括每段20秒的1000個(gè)場景以及140萬幅圖像外,該數(shù)據(jù)集使用了新的3D方法來整合物體檢測,并且發(fā)布了39萬個(gè)激光雷達(dá)掃描輸出。nuScenes不僅需要同時(shí)識(shí)別10類物體(相比KITTI只需預(yù)測單個(gè)類別),還加入了速度和屬性的預(yù)測,而且需要解決嚴(yán)重的類別不均衡問題,因此任務(wù)難度大幅提高,因而也更具有實(shí)際意義。
對(duì)此,曠視設(shè)計(jì)了一個(gè)多尺度、多任務(wù)的模型,借助新型檢測網(wǎng)絡(luò),結(jié)合均衡采樣等策略,極大提高了模型的檢測精度,尤其是在小物體上。由最終結(jié)果可知,相較于官方baseline 45.3%,曠視的模型高出18個(gè)點(diǎn),達(dá)到63.3%,比第二名也高出8.8個(gè)點(diǎn),擊敗一系列頂尖團(tuán)隊(duì),一舉奪魁。

圖:曠視 nuScenes 3D Detection Challenge冠軍獎(jiǎng)牌
CVPR 2019 WAD Detection/Tracking Domain Adaptation Challenge
Detection Domain Adaptation Challenge 是 CVPR 2019 WAD 的另一項(xiàng)挑戰(zhàn)賽,旨在對(duì)自動(dòng)駕駛場景下的環(huán)境(二維圖像信息)進(jìn)行感知,今年的比賽主要解決領(lǐng)域自適應(yīng)問題,即美國道路場景和中國道路場景的相互適應(yīng)。
具體而言,即利用7萬張美國道路場景數(shù)據(jù)進(jìn)行訓(xùn)練,對(duì)近15萬張中國道路場景進(jìn)行測試,不允許使用任何標(biāo)注測試數(shù)據(jù),只允許使用 ImageNet 進(jìn)行預(yù)訓(xùn)練。圖像本身的不一致之外,不同天氣、不同道路以及復(fù)雜的交通狀況都給任務(wù)增加了額外挑戰(zhàn),同時(shí)也為實(shí)際使用提供了可能性。
曠視基于自身積累的檢測算法之外,加之復(fù)現(xiàn)/使用的最前沿的檢測算法(比如 NAS-FPN、Cascade RCNN),進(jìn)而對(duì) Cascade RCNN 做出一系列改進(jìn),使得網(wǎng)絡(luò)在不同 IOU 閾值下的檢測結(jié)果都有一定漲幅;同時(shí),為了解決兩個(gè)數(shù)據(jù)集之間數(shù)據(jù)分布不一致的問題,曠視還利用合并訓(xùn)練、AdaBN、Data Distillation 等技術(shù)手段,最終在測試集上高出第二名深蘭科技1.7個(gè)點(diǎn),同時(shí)在所有單類別上取得最高結(jié)果。

圖:曠視Detection Domain Adaptation Challenge冠軍獎(jiǎng)牌
此外,在 Tracking Domain Adaptation Challenge 上,曠視使用 Online方法進(jìn)行多目標(biāo)跟蹤,即在高精度檢測結(jié)果的基礎(chǔ)上,使用 IOU Tracker 進(jìn)行跟蹤;跟蹤過程中,改進(jìn)和調(diào)試影響結(jié)果的多種因素,最終也在 Tracking 任務(wù)上取得第一。
CVPR 2019 FGVC iNaturalistHerbarium Challenge
CVPR 2019 FGVC 是細(xì)粒度識(shí)別領(lǐng)域最權(quán)威的賽事,iNaturalist Challenge 是此項(xiàng)領(lǐng)域的旗艦比賽,旨在讓計(jì)算機(jī)自動(dòng)識(shí)別物體的精細(xì)類別,它不僅要求識(shí)別1000多個(gè)品種的動(dòng)、植物,還要識(shí)別其在不同發(fā)育期的狀態(tài);Herbarium Challenge 則要解決開花植物野牡丹科的物種分類問題,所采用的圖像集僅包括保存于臘葉標(biāo)本上的干標(biāo)本圖像。
因此,在這兩個(gè)比賽中,除了大模型/大分辨率圖圖像進(jìn)行訓(xùn)練、測試等常規(guī)操作外,曠視還集成最前沿細(xì)粒度技術(shù)成果(比如 Coarse-to-fine hierarchical classification、iSQRT、Class-Balanced Focal Loss 等),同時(shí)創(chuàng)造性提出“后驗(yàn)概率重校準(zhǔn)”技術(shù),即通過先驗(yàn)知識(shí)對(duì)模型輸出的后驗(yàn)概率進(jìn)行校準(zhǔn),極大提高擁有較少訓(xùn)練圖像的長尾類別的識(shí)別準(zhǔn)確率,兩項(xiàng)比賽結(jié)果均高出第2名近1個(gè)點(diǎn),一舉奪魁。
在業(yè)務(wù)方面,商品識(shí)別、菜品識(shí)別、缺陷檢測、生產(chǎn)線零件識(shí)別、車型/車輛識(shí)別等均是細(xì)粒度圖像分析技術(shù)的應(yīng)用,目前已應(yīng)用于產(chǎn)品研發(fā)中。在 iNaturalist 上,曠視擊敗了通用動(dòng)力等頂尖團(tuán)隊(duì);在 Herbarium 上,曠視擊敗了大連理工(上年冠軍)、瑞典自然歷史博物館、Facebook。
CVPR 2019 NTIRE Real Image Denosing Challenge
CVPR 2019 NTIRE Real Image Denosing Challenge 則基于最近新提出的智能手機(jī)圖像降噪數(shù)據(jù)集(Smartphone Image Denoising Dataset, SIDD),它由很多真實(shí)的噪聲圖像及其相應(yīng)的 ground truth 組成,且每幅圖像都有以原始傳感器數(shù)據(jù)(raw)和標(biāo)準(zhǔn) RBG(sRGB)格式存儲(chǔ)的兩個(gè)版本。因此,該項(xiàng)比賽分為了兩項(xiàng)子賽,分別針對(duì) raw 與 sRGB 圖像進(jìn)行去噪,而曠視研究院參戰(zhàn)前者。
事實(shí)上,圖像降噪一直是曠視研究院“手機(jī)攝影超畫質(zhì)”的技術(shù)儲(chǔ)備項(xiàng)目,自第一版原型誕生以后,就在不斷迭代。其中,針對(duì)原始傳感器數(shù)據(jù)(raw)的圖像降噪更是整個(gè)項(xiàng)目的基礎(chǔ)技術(shù)。但就學(xué)術(shù)界來看,對(duì)圖像降噪的關(guān)注點(diǎn)一直以 RGB 圖像為主,對(duì) raw 圖(尤其是手機(jī)上)少有關(guān)注。人們不了解如何對(duì)圖像進(jìn)行前處理、后處理,也不了解在降噪過程中的具體注意事項(xiàng),往往導(dǎo)致無法發(fā)揮數(shù)據(jù)百分百的力量。基于上述背景,曠視研究院希望借此機(jī)會(huì)分享在 raw 圖像降噪上的心得,同時(shí)驗(yàn)證團(tuán)隊(duì)實(shí)力,進(jìn)行進(jìn)一步鍛煉。
在這次比賽中,曠視研究院提出針對(duì) raw 圖像的基于 U-Net 框架的“拜爾陣列歸一化與保列增廣”方法。盡管不同輸入圖像間的數(shù)據(jù)格式存在差異,但是,為保持網(wǎng)絡(luò)輸入一致性,曠視精心設(shè)計(jì)了一種數(shù)據(jù)預(yù)處理方法,使得相同的網(wǎng)絡(luò)工作應(yīng)用到具有不同拜耳模式的輸入上,從而在保證性能的前提下用更大的圖像集合訓(xùn)練網(wǎng)絡(luò)。此外,團(tuán)隊(duì)還提出了適用于 raw 圖像的數(shù)據(jù)增廣方法。這些優(yōu)勢可以幫助網(wǎng)絡(luò)獲得更好的泛化能力(且沒有額外的運(yùn)行時(shí))。
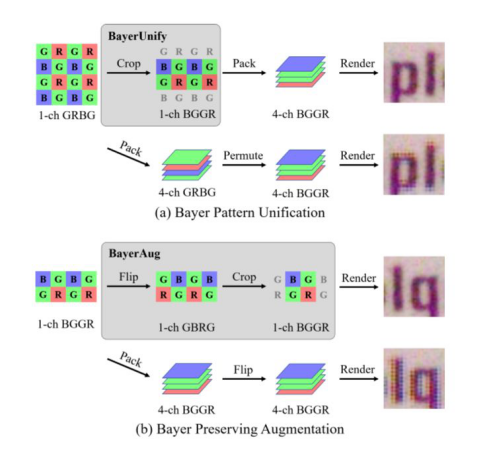
圖:“拜爾陣列歸一化與保列增廣”方法圖示
曠視研究員還發(fā)現(xiàn)了主辦方提供的第一版數(shù)據(jù)集里驗(yàn)證集的錯(cuò)誤,經(jīng)分析,這很可能是由于人們對(duì) raw 圖像處理的知識(shí)相對(duì)不足所造成的。由上述可知,學(xué)界對(duì) raw 圖像展開的圖像降噪研究還處于剛剛起步階段,因此,這個(gè)小插曲從某種層面也說明了對(duì) raw 圖像降噪研究的重要意義。對(duì)于錯(cuò)誤的指出,主辦方及時(shí)進(jìn)行了更正,并向曠視研究院參賽團(tuán)隊(duì)發(fā)來了感謝信。

圖:曠視 Real Image Denosing Challenge 冠軍獎(jiǎng)牌
依托圖像降噪算法,曠視超畫質(zhì)技術(shù)在智能降噪的同時(shí),能夠更好地保留畫面質(zhì)感,大幅度優(yōu)化拍攝和影像處理的時(shí)間,顯著提升用戶在夜晚和低光照環(huán)境下的拍攝體驗(yàn)。目前,該算法已成功落地于 OPPO Reno 10 倍變焦版。OPPO Reno 10 倍變焦版搭載了基于曠視 MEGVII 超畫質(zhì)技術(shù)研發(fā)的“超清夜景2.0”功能,能夠?yàn)橛脩籼峁┓峭岔懙囊古捏w驗(yàn)。這也是曠視超畫質(zhì)技術(shù)首次運(yùn)用在大規(guī)模量產(chǎn)機(jī)型上。
能夠在CVPR 2019滿載而歸,對(duì)曠視而言意義重大。曠視首席科學(xué)家、曠視研究院院長孫劍表示:“一流的人才往往希望在一個(gè)開放的環(huán)境中成長。發(fā)表論文、參加學(xué)術(shù)會(huì)議,其實(shí)是有人對(duì)你的工作鼓掌,激勵(lì)你繼續(xù)前行。曠視研究院最寶貴的財(cái)產(chǎn)是人才。如何吸引、培養(yǎng)、保留人才是一個(gè)組織健康和高速發(fā)展最關(guān)鍵的。我的工作第一優(yōu)先級(jí)是打造一個(gè)好的研發(fā)環(huán)境,讓公司贏,讓我們贏,讓每個(gè)人贏。因?yàn)槲沂冀K相信兩點(diǎn):中國不缺乏聰明人,中國有世界上最好的發(fā)展機(jī)會(huì)。我們就是要把一幫聰明人聚起來,齊心協(xié)力,貫徹‘發(fā)展就是硬道理’。”
值得一提的是,曠視能夠在CVPR 2019斬獲六項(xiàng)冠軍的背后源自曠視深度學(xué)習(xí)框架 Brain++的有力支撐作用。Brain++是一套由曠視研究院自主原創(chuàng)的算法引擎,致力于從云、端、芯三個(gè)方面全面賦能物理世界,以實(shí)現(xiàn)對(duì)世界的感知、控制、優(yōu)化。Brain++ 不僅助力曠視拿下世界冠軍,在未來,還將推動(dòng)智能汽車、商品識(shí)別、手機(jī)影像處理、智慧農(nóng)業(yè)等應(yīng)用領(lǐng)域的進(jìn)步發(fā)展。

陳熙一