
科技改變生活 · 科技引領(lǐng)未來
科技改變生活 · 科技引領(lǐng)未來

1.概述
TTS(Text To Speech)又稱語音合成,是一種將文本轉(zhuǎn)化成相應(yīng)語音的技術(shù)。TTS技術(shù)從誕生到現(xiàn)在已經(jīng)有200多年的歷史。在1779年,德國科學(xué)家Kratzenstein首次開發(fā)出五個(gè)長元音的人類聲道模型,并于1791年加入了舌頭和嘴唇模型,實(shí)現(xiàn)元音輔音的聲道模型。隨后TTS技術(shù)陷入了漫長的沉寂期,直到20世紀(jì)30年代和70年代,兩大技術(shù)的突破大大推動(dòng)了TTS技術(shù)的發(fā)展,1939年,貝爾實(shí)驗(yàn)室制作出了第一個(gè)語音合成器The Voder,1979年MIT開發(fā)出了著名的語音合成系統(tǒng)MITalk。1992年,PSOLA(基因同步疊加技術(shù))的提出使合成的語音更加自然。21世紀(jì)以來,基于HMM的語音合成系統(tǒng)和基于神經(jīng)網(wǎng)絡(luò)的語音合成系統(tǒng)逐漸成為研究主流,并取得良好的效果。目前,TTS已廣泛應(yīng)用到日常的生活當(dāng)中,如語音助手、智能音箱、地圖導(dǎo)航等。
2.TTS系統(tǒng)現(xiàn)狀
對(duì)于早期的語音合成系統(tǒng)來說,只要發(fā)音清晰,內(nèi)容流暢并完全可懂就可以算是一個(gè)優(yōu)秀的系統(tǒng)了。但是隨著時(shí)代發(fā)展,技術(shù)的進(jìn)步以及應(yīng)用場(chǎng)景的細(xì)化,這類系統(tǒng)已經(jīng)遠(yuǎn)遠(yuǎn)不能滿足人們的需求。目前業(yè)界的TTS系統(tǒng)主要分為通用性TTS,個(gè)性化TTS,情感TTS三類。
通用性TTS:這類TTS系統(tǒng)基本已經(jīng)達(dá)到可以商用的地步了,但是由于依舊存在機(jī)械感,不能模擬自然人聲的原因,如果用戶預(yù)期較高的話很難滿足用戶需求。
個(gè)性化TTS:在特定的應(yīng)用場(chǎng)景下這類TTS系統(tǒng)基本能滿足商用,但是效果沒有通用TTS好。目前以科大訊飛為代表的人工智能企業(yè)具備成熟商用所需的技術(shù)能力。
情感TTS:隨著TTS技術(shù)的發(fā)展和數(shù)據(jù)量逐漸增多,業(yè)內(nèi)研究機(jī)構(gòu)逐步開啟了情感TTS合成技術(shù)研究。情感TTS系統(tǒng)的開發(fā)更加側(cè)重于自然語言處理方面,如“情感意圖識(shí)別”、“情感特征挖掘”等技術(shù)。情感TTS比傳統(tǒng)的TTS節(jié)奏性更強(qiáng),自然性也更好,但就應(yīng)用落地來說還處于初步階段。
無論對(duì)于哪種TTS系統(tǒng)來說,在技術(shù)相差不大的情況下,聲優(yōu)質(zhì)量和數(shù)據(jù)量尤為重要。目前對(duì)于TTS系統(tǒng)來說問題之一是數(shù)據(jù)缺乏,尤其是個(gè)性化TTS對(duì)于數(shù)據(jù)量的要求更大,另一方面數(shù)據(jù)制作的周期長和成本高,都對(duì)TTS數(shù)據(jù)生產(chǎn)提出了更高的要求。下文著重在TTS數(shù)據(jù)制作方面做出介紹。
3.TTS數(shù)據(jù)制作流程
3.1語料制作
語料制作環(huán)節(jié)需遵循覆蓋基本音素組合的原則,然后根據(jù)具體使用場(chǎng)景決定語料領(lǐng)域是否要有所偏重。語料的制作需要考慮語料來源、語料長度和語料的量級(jí)。語料來源可通過爬取、造句等方式生成,之后經(jīng)過人工校對(duì)(去除拗口、有語病的語料),形成最終語料。語料的長度不同任務(wù)要求不同,以中文TTS數(shù)據(jù)為例,單句的長度在12-15字為宜。語料的數(shù)量要求主要取決于TTS系統(tǒng)的級(jí)別,簡(jiǎn)易的TTS系統(tǒng)要求數(shù)據(jù)量在3000-5000句之間,一般程度的系統(tǒng)需求數(shù)據(jù)量在15000句,更為高級(jí)的最低要求數(shù)據(jù)量就在20000句以上。
3.2錄音人挑選
傳統(tǒng)TTS對(duì)錄音人要求較高,目前隨著個(gè)性化TTS系統(tǒng)的需求量增大,TTS數(shù)據(jù)制作過程中錄音人為播音專業(yè)學(xué)生的最低要求也有所放寬,甚至普通人也能參與到數(shù)據(jù)制作中。錄音人的選取首先要基于TTS系統(tǒng)應(yīng)用語種(英文、普通話、方言等)、朗讀風(fēng)格(播音、正常說話、童音、二次元等)和錄音人性別年齡分布劃定錄音人范圍。錄音人范圍確定后需要進(jìn)行錄音人的篩選工作,首先需要搜集錄音人信息及錄音小樣,經(jīng)過第一輪篩選挑出3-5人,然后在錄音棚實(shí)際錄音50-100句/人,最終經(jīng)過第二輪綜合篩選確定錄音人,整個(gè)過程至少需要3-4周。
3.3錄音環(huán)境
TTS數(shù)據(jù)對(duì)于錄制環(huán)境要求嚴(yán)格,需要在專業(yè)錄音棚中錄制并嚴(yán)格控制噪聲水平,最大限度還原發(fā)音人發(fā)音。錄音過程中需要有專業(yè)錄音師和監(jiān)聽人在場(chǎng),及時(shí)矯正錄音過程中的錯(cuò)誤(如:口水聲、噴麥、咂嘴等錄音人引起噪音,發(fā)音錯(cuò)誤,突發(fā)噪音等)。
3.4正式錄音
正式錄音開始前,監(jiān)聽人員需要跟錄音人磨合語速風(fēng)格,然后選擇2-3句錄音作為基準(zhǔn)參考發(fā)音,由現(xiàn)場(chǎng)監(jiān)聽人員把控,每錄20-30句向錄音人播放基準(zhǔn)參考發(fā)音。當(dāng)錄音人出現(xiàn)音質(zhì)變化時(shí),現(xiàn)場(chǎng)監(jiān)聽人員具有一票否決權(quán),并可隨時(shí)決定是夠繼續(xù)錄音。另外,為保證錄音質(zhì)量,原則上錄音人在錄音棚時(shí)間不能超過4小時(shí)。
3.5數(shù)據(jù)標(biāo)注
3.5.1文本標(biāo)注
文字標(biāo)注內(nèi)容根據(jù)發(fā)音人實(shí)際發(fā)音做一致性標(biāo)注,例如“1990-2-24”需要根據(jù)實(shí)際錄音轉(zhuǎn)寫成“一九九零年二月二十四日”。
3.5.2音素標(biāo)注
中文使用聲母韻母系統(tǒng)標(biāo)注,西文使用IPA進(jìn)行標(biāo)注。以中文為例,標(biāo)注效果為:
原句:腦袋大就聰明嗎?
音素:nao3 dai4 da4 jiu4 cong1 ming2 ma5?
音素標(biāo)注會(huì)遇到錯(cuò)讀、輕聲和連續(xù)變調(diào)等典型問題,可基于下述方案解決:
讀錯(cuò)字:標(biāo)注時(shí)按照實(shí)際發(fā)音標(biāo)注;
輕 聲:標(biāo)注時(shí)按照實(shí)際發(fā)音標(biāo)注;
連續(xù)變調(diào):遵從普通話變調(diào)規(guī)則,一不變調(diào)、三三變調(diào)
3.5.3音素切分
按照實(shí)際語音情況,標(biāo)注出每個(gè)音素的起止時(shí)間點(diǎn),此處對(duì)于標(biāo)注員要求較高。
3.5.4詞性標(biāo)注
標(biāo)記每個(gè)字所屬詞的詞性,對(duì)于中文來說基本有39中詞性,常見的有:a(形容詞)、m(數(shù)詞)、n(名詞)、ns(地名)、p(介詞)、j(簡(jiǎn)稱略語)、d(副詞)等,標(biāo)注效果如下:
Eg:美國/ns 對(duì)/p 港/j 澳/j 政策/n 不/d 會(huì)/v 改變/v 。
3.5.5韻律標(biāo)注
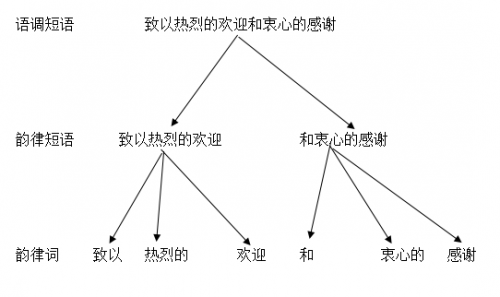
韻律又稱超音段特征、節(jié)律或音律,包括節(jié)奏、強(qiáng)調(diào)、語調(diào)等。因?yàn)檠哉Z信息在時(shí)間線上是先后依次出現(xiàn)的,但實(shí)際上并不是線性平均分配,而是以層級(jí)形式分布的,所以韻律標(biāo)注一般包含四級(jí),分別為:韻律詞、弱韻律短語、強(qiáng)韻律短語、語調(diào)短語。
韻律詞:是韻律層級(jí)結(jié)構(gòu)中的基本單位,指口語中緊密連在一起發(fā)音的幾個(gè)音節(jié)的組合,單音節(jié)詞往往會(huì)跟相鄰的雙音節(jié)詞共同構(gòu)成一個(gè)韻律詞(如:“引起了”中的“了”,通常與前面的雙音節(jié)詞“引起”共同組成一個(gè)韻律詞),包含超過三個(gè)音節(jié)的詞,往往會(huì)被分解成多個(gè)雙/三音節(jié)韻律詞。不同韻律詞邊界不停頓或聽感不可察覺停頓。
弱韻律短語:由一個(gè)或一個(gè)以上韻律詞構(gòu)成,每個(gè)弱韻律短語后有較短的停頓或靜音,發(fā)音方面具有音高不下傾或稍下傾的特點(diǎn)。另外韻末不可以用作句末。
強(qiáng)韻律短語:由一個(gè)或多個(gè)弱音律短語構(gòu)成,每個(gè)強(qiáng)韻律短語后可以感知到明顯的停頓,音高曲線有明顯的下傾。
注意:增加層級(jí)會(huì)增加復(fù)雜度,所以有時(shí)候會(huì)將弱韻律短語和強(qiáng)韻律短語作為一個(gè)層級(jí)標(biāo)注
語調(diào)短語:由一個(gè)或多個(gè)強(qiáng)韻律短語構(gòu)成,每個(gè)語調(diào)短語后會(huì)有較長的停頓且末尾音節(jié)韻律上會(huì)有延長,這種短語一般位于句末,具有特定的語調(diào)模式。語調(diào)模式的音調(diào)走勢(shì)由具體的語氣或句型決定,如陳述句為降調(diào)、疑問句為升調(diào)、感嘆句為總體音調(diào)上升。
為了更好地理解韻律標(biāo)注各個(gè)層級(jí)間的關(guān)系,我們可以下方關(guān)系圖:
4.TTS系統(tǒng)展望
目前,合成語音的可懂度、自然度已經(jīng)達(dá)到用戶可接受的程度,TTS系統(tǒng)也已進(jìn)入大規(guī)模產(chǎn)業(yè)化的應(yīng)用階段。隨著互聯(lián)網(wǎng)時(shí)代用戶對(duì)信息獲取途徑的多樣性需求,語音合成技術(shù)將迎來巨大的機(jī)會(huì)。例如:最近由Dessa開發(fā)出的RealTalk語音合成系統(tǒng),僅需要通過輸入文本即可生成堪比真人的聲音,也就是說在獲得足夠訓(xùn)練數(shù)據(jù)的先決條件下,該系統(tǒng)可以復(fù)制任何人的聲音。這項(xiàng)技術(shù)可能是一個(gè)重大突破,這也預(yù)示著可能在未來的十幾年甚至幾年,技術(shù)可能發(fā)展到只要短短幾分鐘的音頻便可以模仿出任何一個(gè)人的聲音。
語音合成技術(shù)的發(fā)展,一方面取決于技術(shù)上的進(jìn)步,另一方面取決于商業(yè)化應(yīng)用能否擴(kuò)大市場(chǎng)。從技術(shù)上來說情感語音合成、個(gè)性化語音轉(zhuǎn)換等是目前的研究方向,從市場(chǎng)角度出發(fā),如何開發(fā)出成熟的TTS應(yīng)用并獲得用戶認(rèn)可才是關(guān)鍵。

李原一