
科技改變生活 · 科技引領未來
科技改變生活 · 科技引領未來

IT人都知道:768k日快要來了。
據專家估計,就在5月,還有可數的20來天吧。
所以,網絡上充斥著對768k日緊張又期待、忐忑又興奮、謹慎又樂觀的各種猜測和預測。
這種酸爽復雜的心緒,就像是迎接初戀......
無論從哪個角度看,768k日都不算是初戀啦。前有大名鼎鼎的互聯網故障之母:512k日(512k Day),這場發生在2014年8月12日的意外事故,令當時全球各地的數百家互聯網服務提供商(ISP)癱瘓,造成了因連接中斷或數據包丟失而導致的損失高達數十億美元。
512k Day & 768k Day 的背景
512k日之所以會發生,是由于路由器用來存儲全局BGP路由表的內存不足,BGP路由表是一個文件,包含所有連接至互聯網的已知網絡的IPv4地址。當時,互聯網的大部分系統通過分配TCAM(三元內容可尋址內存)的設備進行路由;TCAM足夠大,存儲最多512000條互聯網路由。
但在2014年8月12日那天,韋里遜增加了15000條新的BGP路由,這導致全局BGP路由表在沒有警告的情況下突然超過512000條。在舊路由器上,這表現為全局路由表文件從分配的內存中溢出,每次嘗試讀取或處理該文件都會使設備崩潰。微軟、eBay、LastPass、BT、LiquidWeb、康卡斯特、AT&T、斯普林特和韋里遜等公司統統受到了影響。
許多老式路由器都收到了緊急固件補丁,讓網絡管理員得以為分配用于處理全局BGP路由表的內存大小設置更高的閾值。大多數網絡管理員都遵循當時提供的文檔,將新的上限設置為768000,即768k。
近期,多方數據顯示:全局BGP路由表在舊路由器上即將達到768000的限制——CIDR Report是跟蹤全局BGP路由表的網站,它估計該文件的大小是773480個條目,但其中含有一些重復條目;一個名為BGP4-Table的Twitter機器人程序也一直在跟蹤全局BGP路由表的大小,它估計文件的實際大小為767392,離溢出僅一步之遙。
好消息是:不少專家認為768k日不會像2014年那樣引起整個互聯網的中斷。由于很多網絡管理員早就知道了768k日,許多人已作好了準備,要么把舊的路由器換成新的;要么調整固件,允許設備處理超過768000條路由的全局BGP路由表。
但,我們不禁要問:隨著路由表的不斷累積增大,難道這閾值就這樣一直調整下去嗎? 512k日之后有768k日,接下來呢,會不會還有1024k日、2048k日呢?
表項空間不足的問題不僅給我們帶來了512k日、768k日這些網絡運維的麻煩,也給云數據中心的規模擴展和性能提升造成了束縛和困擾。
下圖描述了在傳統底層網絡中,將二層虛擬網絡卸載到底層網絡的Leaf交換機上、并且采用EVPN在所有的Leaf交換機之間傳遞所有虛擬網絡的所有虛擬計算節點的網絡可達信息時的情景:
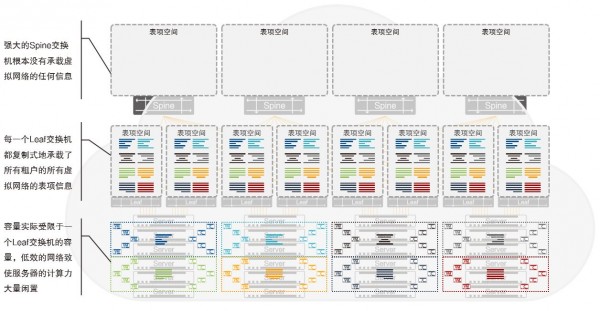
所有二層虛擬網絡的VTEP功能被從物理服務器上遷移到Leaf交換機上部署,因此,每一個Leaf交換機的FIB(ForwardingInformation base,轉發信息表)需要裝載的信息包括兩類:
* 它自己連接的所有物理服務器中運行的所有虛擬計算節點的轉發信息,簡稱為本地虛擬計算節點信息
* 與所有本地虛擬計算節點處于同一個二層虛擬網絡中的、運行于其他Leaf交換機下的物理服務器中的所有虛擬計算節點的轉發信息,簡稱為遠端虛擬計算節點
再考慮到二層虛擬網絡之間的互通、三層虛擬網絡網關的分布式部署等因素,我們可以近似地認為,在上面的方案中,每一臺Leaf交換機都需要在其FIB中裝載全網(或全云)所有租戶的所有虛擬網絡的所有虛擬計算節點的轉發信息。而且,更為嚴峻的是,這樣的信息在所有Leaf交換機上完全是高度地重疊,即每一臺Leaf交換機都無差別地復制、承載了所有信息。換句話說:一臺Leaf交換機的FIB表項空間的大小,直接決定了云中的虛擬計算節點的數量。而Spine交換機的FIB空空如也,除了底層網絡很少的那一點點轉發信息以外,沒有裝載任何跟虛擬網絡和虛擬計算節點相關的信息……
以一個可容納5,000臺物理服務器的中小規模的云數據中心為例,將其最低虛擬計算節點容量設計為5,000,000是一個最正常的需求。但是,在今天的商業以太網交換芯片市場上,為1RU高的Leaf交換機設計的交換芯片的FIB表項空間的容量最常見的只有128K,做的最大的也就僅512K而已。
由此,5,000,000和512K的矛盾就尖銳地凸顯出來了。
在這種矛盾面前,不得不做出的妥協就是:為了追求將VXLAN的功能卸載到物理交換機上,不得不將整張云能夠支持的虛擬計算節點的數量進行數量級的降低;甚至,干脆棄用明顯具備性能優勢的“硬件/EVPN方案”,退回到“vSwitch方案”的世界里,用耗費大量計算力模擬網絡功能和大幅降低整體性能的成本來換取非常有限的容量提升。
那么,表項空間的難題,有沒有更好的解決方案呢?
重點來了——當然有!它就是PICFATM,Protocol Infinity Cloud Fabric Architecture,協議無限云網架構。它是Asterfusion(星融)為下一代云網絡全面創新的分布式架構。
PICFA采用獨創的分布式路由算法和與之相配合的轉發邏輯,完全重構了云網絡的控制平面與數據平面,徹底拋棄了傳統網絡中低效的集中式存儲結構與轉發邏輯,將云網絡對云中虛擬計算節點的容量支持一舉提升100倍至千萬量級,同時大幅提升轉發性能,使網絡不再成為云計算容量的限制因素,從而為云網絡從計算空間向底層物理網絡的遷移打下堅實的基礎。
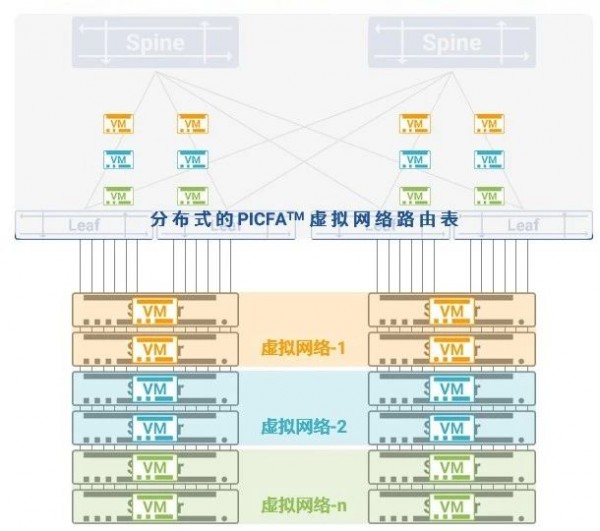
PICFA將Asterfusion(星融)云網絡所有交換機的能力整合為一個超級的“分布式虛擬路由表”。在部署了PICFA的云網絡中,所有租戶的所有虛擬網絡信息被動態、智能、均衡地分布在全網的所有Spine和Leaf交換機上,充分利用所有交換機的所有表項空間,由此,單臺網絡設備的FIB容量不再成為云的容量限制,虛擬機數量獲得量級的提升,服務器計算力被充分利用。
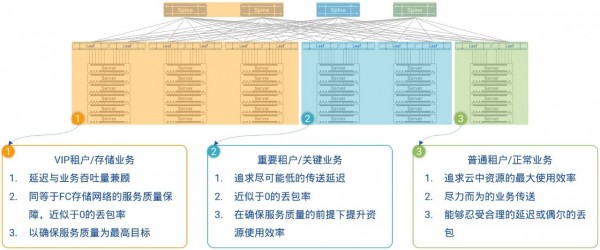
此外,所有Spine交換機可被動態地劃分為三組,其中第三組可以被指定用來承載VIP租戶和/或關鍵業務,這組Spine交換機將會被PICFATM從物理上與其他Spine交換機隔離開來,運行在HULL架構(High-bandwidth Ultra-Low Latency Architecture)所描述的資源使用率較低的狀態下,從而真正做到了物理隔離,讓低優先級租戶的流量和盡力傳送型業務流量對VIP租戶和業務的影響降至0,完全達到SLA(Service Level Agreement)所規定的服務質量保證,即極低的網絡延遲和近似于0的丟包率。
最后,做個總結吧!
▼
由于采用了專利算法,PICFA不僅一勞永逸的解決了表項空間的問題,而且將網絡對云的支撐能力提升了100倍,將單數據中心可制成的虛擬計算節點數量一舉提升到千萬量級,為大規模公有云向更多的租戶提供業務支撐打下堅實的基礎。所以,采用PICFA構建的Asterfusion(星融)云網絡,可以成功突破服務器內部10G帶寬的物理限制,緊密跟隨基礎網絡的發展速度,進入到100G/400G時代,成為名副其實的超高性能網絡。
也正是因為有了PICFA,Asterfusion(星融)才一直走在“讓云網絡回歸網絡”的征途上。區別于傳統云網絡中被定義為“粗但是傻”的底層線路,Asterfusion將底層網絡重新定義為“粗并且靈”的智能網絡,為云中租戶與業務服務的虛擬網絡直接承載在其上,在提供虛擬化、多租戶的同時,支持NFV等增值功能,讓云的ROI“里外里”地增長。

劉悅明