
科技改變生活 · 科技引領未來
科技改變生活 · 科技引領未來

面向異構眾核超級計算機的大規模稀疏計算性能優化研究胡正丁,薛巍清華大學計算機科學與技術系1引言近年來,隨著計算機系統和大數據技術的發展,大規模數值計算、科學計算等在大型異構并行系統上的應用逐漸深入。從對自然現象的模擬和預測到工程學設計和產品
面向異構眾核超級計算機的大規模稀疏計算性能優化研究
胡正丁, 薛巍
清華大學計算機科學與技術系
1 引言
近年來,隨著計算機系統和大數據技術的發展,大規模數值計算、科學計算等在大型異構并行系統上的應用逐漸深入。從對自然現象的模擬和預測到工程學設計和產品研發,超級計算(以下簡稱超算)在這些領域發揮著不可或缺的作用。與此同時,應用的需求反過來也促進了超級計算機的發展,更大型超級計算系統的構建使得更多富有挑戰性的任務的解決成為可能。
大規模計算往往與大數據,特別是大規模稀疏數值問題緊密相連。數值天氣預報通過數值計算求解描述天氣演變過程的流體力學和熱力學的方程組,以預測未來的大氣運動狀態和天氣現象。若在全球采取千米級分辨率,會產生百億規模的計算網格,相應的聯立方程組規模會達到千億級別。7天左右的天氣預報需要約6萬步迭代,而涉及氣候預測的時間跨度甚至多達數年,其中的計算規模和數據規模是難以想象的。在線網絡欺詐分析結合大數據和人工智能技術檢測網絡欺詐行為,需要保證預測結果的準確性和實時性。全球的中文網頁約有2 700億個,鏈接數量達12萬億個,相應網頁圖存儲規模達到137 TB,這無疑對數據存取和算法運行效率提出了很高的要求。
稀疏問題的計算核心(如稀疏矩陣運算和圖遍歷等)在大規模計算中廣泛存在。天氣預報、地震分析等自然現象模擬過程需要對大規模偏微分方程進行求解,其中涉及頻繁的稀疏矩陣運算操作。而蛋白質交互、基因工程和腦科學等科學研究工作需要對大規模稀疏圖進行生成、遍歷和處理。
超級計算機系統由于具有強大的存儲和計算能力,成為解決大規模稀疏問題的有效選擇。而由于其訪存和計算模式的特殊性質,稀疏問題在并行和分布式計算機系統上的求解成為一個難題,具體體現在任務劃分、計算調度、存儲管理和功耗管理等多個方面。超級計算機給稀疏問題求解帶來了全新的機遇和挑戰。
因此,本文針對基于異構眾核的超級計算機——“神威·太湖之光”的大數據稀疏問題解決和優化方案進行闡述,探討異構眾核計算機架構下大規模稀疏計算性能優化的一般性方法,為在新一代異構眾核系統上開展大規模稀疏計算問題求解提供借鑒。
2 稀疏問題的計算挑戰
因為稀疏問題具有非規則的計算與訪存特征,所以其在大規模超級計算機中的求解面臨嚴峻的挑戰,主要包括以下幾點。
(1)不規則的主存儲器訪問
隨著CPU主頻的提高和處理器計算能力的不斷增強,CPU運算速度與主存帶寬不匹配的問題越來越嚴重。與計算密集型應用不同,稀疏計算核心的計算訪存比往往較低。典型的稀疏計算問題(如稀疏矩陣向量乘法、基礎向量矩陣運算、模板計算等)只有常數級別的計算訪存比,而其余典型算術核心(如渦格法、快速傅里葉變換、粒子法)的計算訪存比會達到O(logN)甚至O(N)的級別。因此對于稀疏計算型應用而言,存儲器訪問的開銷可能遠遠超過計算本身帶來的開銷,使得訪存問題成為應用開發過程中需要重點關注的部分。
計算機系統的存儲器架構往往是多級的。靠近處理器的存儲層級一般存取速度快,但容量較小;反過來,遠離處理器的存儲層級容量大、速度慢。對于大規模計算機系統而言,這種容量和計算速度的對比往往更加夸張。因此,要解決應用的訪存問題,需要解決大規模稀疏數據的存儲管理策略問題,盡量將頻繁使用的數據放在高層級,減少低層存儲器的訪問次數,同時做好數據的分塊和搬運策略,增強訪存的連續性和一致性。
稀疏型計算問題的訪存模式是不規則的。稀疏計算問題的數據局部性較差,可能存在離散化、隨機化、不規則訪存的問題,隨機化訪存對數據分塊和局部化并不友好,而細粒度訪存會導致不同節點的競爭,增大存儲總線的壓力。稀疏計算問題的這種特性給開發者的存儲管理策略帶來了許多困難。
此外,傳統的動態隨機存取存儲器(dynamic random access memory, DRAM)價格昂貴、能耗高、性能不穩定,給許多大數據稀疏問題的解決帶來了限制。近年來出現了大量的新型非易失性存儲器(non-volatile memory,NVM),它們具有價格和能耗較低、容量大、性能高的特點,給內存存儲與計算模式帶來了巨大的變革,新型內存計算技術正在蓬勃發展。為了充分利用NVM容量大和DRAM讀寫性能好的優勢,并且最大限度地避免各種存儲介質的缺陷,DRAM-NVM異構內存系統的設計與優化成為研究的熱點。這種異構系統的實現面臨體系結構、系統軟件、編程模型等多個層面的挑戰,相關研究工作已經提出了具有針對性的解決方案。例如,相變存儲器(phase change memory,PCM)就是非易失性存儲器的一種,其存儲密度較高、持久性強,有學者通過將PCM與DRAM結合來構建優勢互補的混合存儲架構。
(2)可并行化與負載均衡
部分稀疏計算核心可能存在非規則的計算模式。比如,在求解線性方程組用到稀疏矩陣LU分解(LU factorization)與稀疏三角矩陣方程求解(sparse triangular solver,SpTRSV)的過程中,不同位置的數據具有計算依賴關系,存在求解的先后順序。在模板計算中,每個進程需要等待halo區,也就是由其部分鄰居進程負責計算的數據區域完成后才可開始下一步計算。這種基于數據依賴的非規則計算模式使得傳統分塊并行方法不再適用,開發者需要最大限度地挖掘應用中可并行化的部分。
同時,多核計算機系統中每個處理器的負載也是需要考慮的問題。稀疏矩陣中的非零元排布如圖1所示,其中b和x分別表示矩陣的行和列兩個維度。在一個稀疏矩陣中,不同行/列間的非零元分布密度可能存在巨大差別。如果采用靜態分塊方法,會導致不同處理器負責計算的非零元數目不均衡。這種不均衡不僅會大大降低應用的性能,還可能造成部分處理器資源的浪費,增大應用運行的功耗和成本。這對大規模稀疏問題的問題劃分和任務分配提出了更高的要求。
(3)數據傳輸與通信
在大規模異構計算機系統上,稀疏問題的求解往往涉及頻繁的進程間/節點間通信。這種通信給I/O和節點間網絡帶來了巨大壓力。隨著眾核架構的廣泛使用,處理器主頻和單核的計算能力受限,原有的超算基礎軟件(如MPI通信庫)主要面向進程通信開發,其中的大量計算功能依賴單核的計算能力,已經無法滿足新的架構需求;同時,隨著管理進程數的增加,超算基礎軟件本身的內存開銷成為一個不可忽視的問題,這些都成為限制大數據稀疏應用性能提升的關鍵因素。
隨著超算規模的增大,相對固定的系統配置無法與多種多樣的應用計算和通信模式有效匹配,同時在通信、I/O層面的應用相互干擾問題愈加突出。通信瓶頸往往會對應用性能的可擴展性與穩定性造成影響。因此,如何解決數據的傳輸和通信問題,對于應用開發者來說是一項挑戰。
在大數據時代,應用的問題規模和相應的數據規模呈爆炸式增長,大量非結構化數據的出現使得提取信息的難度越來越大,也對外存儲器的訪問效率提出了更高的要求。顯然,基于磁盤的存儲系統已經難以滿足日益增長的訪問需求。與磁盤相比,閃存(flash memory)具有體積小、能耗低、帶寬高、時延低、抗震性強、可靠性高等特點,研究人員正著力于構建大規模閃存存儲系統,以充分發揮閃存優勢,適應大數據環境的發展。
3 異構眾核架構及挑戰
本文以典型的異構眾核超級計算機——“神威·太湖之光”中的申威26010眾核處理器(SW26010)為例,介紹異構眾核架構及其應用開發的挑戰。
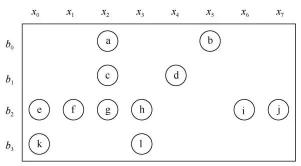
圖1 稀疏矩陣中的非零元排布
3.1 異構眾核架構設計
圖2所示為典型的采用異構眾核架構的申威26010眾核處理器,每個處理器包含4個核組,每個核組通過片上網絡互聯,并通過PCI-E 3.0對外連接。每個核組獨立運行,包含一個控制核心(主核)、64個運算核心(從核)和一個內存控制器。整個處理器可以提供3.06 TFlops的雙精度浮點計算峰值性能和136 GB/s的理論總內存帶寬。
主核擁有常規的兩級Cache系統,通常被用于執行管理和通信任務。從核具有很高的浮點運算性能,通常被用于執行計算任務。與常規的緩存方式不同,每個從核包含一個大小為64 KB的便箋存儲器(local data memory,LDM)。LDM由靜態隨機存取存儲器(static randomaccess memory,SRAM)設計,與主存DRAM的地址空間分離,并對用戶可見,用戶需要顯式地控制數據在主存和LDM之間的傳輸。每個核組的64個從核構成8×8的網格陣列,每兩行從核共享一條連接到內存控制器的總線。從核訪問主存的方式有兩種:一種是通過全局讀入(gload)和寫出(gstore)指令實現內存-寄存器的數據傳輸,這種方式粒度較細,更加靈活,但帶寬只能達到1.5 GB/s;另一種是通過直接內存訪問(direct memory access,DMA)實現內存-LDM的數據傳輸,再通過訪問LDM來獲取數據。DMA是一種粗粒度的訪存模式,根據StreamTriad測試,64個從核同時通過DMA訪存可以獲得22.6 GB/s的帶寬。
SW26010另一個獨特的設計是從核陣列上的寄存器通信技術。根據StreamTriad測試,寄存器的通信時延僅11個指令周期,集合帶寬超過600 GB/s。在8×8的網格陣列中,同一行或同一列的從核可以高速互傳數據。每個從核都有一個發送緩沖區、一個行接收緩沖區和一個列接收緩沖區。在寄存器通信中,硬件會將發送緩沖區內的數據放到目標從核的行/列接收緩沖區中。這個過程以阻塞方式自動進行,直到發送緩沖區為空或者接收緩沖區已滿。
3.2 異構眾核架構的挑戰和開發技巧
異構眾核架構擁有與常規并行程序開發不同的編程和優化模式。這種不同為大規模并行程序帶來巨大性能潛能的同時,也給程序開發者提出了更多的要求。“神威·太湖之光”把并行度推進到千萬核級別,因而也對數值型應用和優化方法的可擴展性提出了挑戰。因此,在開發過程中應當注意以下幾個方面。
(1)充分發揮從核運算性能
SW26010每個核組內的從核可以使用SunwayOpenACC或Athread實現并行執行。根據性能指標計算,SW26010上的主核浮點性能約為23.2 GFlops,而從核浮點性能達到了742.4 GFlops。由于這種浮點性能上的巨大差距,要提升計算密集型程序的運行效率,就需要盡可能充分地發揮從核的運算性能,充分發掘應用內部的并行性。
由于從核的數目和物理拓撲關系相對固定,以及從核LDM大小和內存帶寬的限制,應用內部的子問題劃分需要具有足夠的局部性,同時也要考慮從核陣列的排布特點。非同行/列的從核間無法直接進行寄存器通信,可能需要其他從核參與,這會顯著增加從核間寄存器通信的開銷,因此最好將相鄰的任務分配到相同的行/列上。由于每兩行從核之間共享一條內存總線,要想提升內存帶寬,就需要充分利用4條內存總線,將內存訪問均勻地分配到每條總線上。對于一些計算和訪存不規則的應用,簡單的分塊方法可能造成從核間負載不均衡,因而無法完全發揮處理器的性能。這些都對并行問題的劃分提出了較高的要求。
(2)充分利用LDM,減輕主存壓力
SW26010主存和局部存儲器的訪問性能差異尤其明顯,從核進行離散化訪存的開銷是高昂的,全局離散存/取(gload/gstore)指令需要超過200個時鐘周期,而訪問局部存儲器LDM僅需4個時鐘周期。因此,要提升并行程序的運行效率,就要充分利用LDM局部存儲器,減少全局內存訪問,設計好的緩存策略。SW26010的獨特架構將緩存策略的設計交給開發者,這一做法更加增加了這一問題的重要性和難度。SW26010的從核LDM大小為64 KB,顯然無法滿足所有應用對局部數據的需求。在一些程序中,頻繁的主存-LDM交換是可能存在的,而減少交換次數、提高交換效率是開發者需要考慮和實現的。合理的LDM管理策略是提高申威架構下程序運行效率的關鍵點之一。
從核DMA的帶寬高達22.6 GB/s,而gload/gstore指令的帶寬只有不到1.5 GB/s。另外,DMA可以在數據傳輸過程中解放CPU,實現計算-訪存重疊模式,縮短時延。因此,連續化、聚合化的DMA訪存可以有效提升訪存效率,而部分應用的不規則訪存模式增大了使用DMA的難度。
值得注意的是,申威架構的DMA效率在特定情況下可達到峰值。對于隨機化訪存,DMA操作性能會在256 B及以上的粒度下達到峰值。另外,由于DMA是以128 B大小的塊為單位進行訪問的,因此數據需要按照128 B對齊,以充分發揮其性能。稀疏計算型應用常常涉及對主存中多個數組的離散化、細粒度的訪問,這種訪問模式很難充分發揮DMA操作的性能,因此需要對數據布局進行調整。對于多個具有相似的訪問模式的數組,可以將其合并,即將包含多個數組的結構體(structure of arrays,SOA)轉化為一個大的包含多個元素的結構體的數組(arrays of structures,AOS)。如果合并后的結構體不滿足內存對界要求,可以適當地加入空位(padding)進行填補。
對于難以合并的、訪問模式獨立的數組,可以對數組的數據分布進行調整。比如,在地震模擬應用中,在主存中開辟出額外的存儲空間,用于存儲每個進程需要訪問的劃分后的包含halo區的數組部分,這樣可以保證DMA操作的連續性,減少內存訪問操作的頻率。
數據結構的調整可以有效解決稀疏問題的細粒度訪存問題,提升稀疏型應用在申威架構下的訪存帶寬。
(3)充分運用從核間通信
從核間高效的寄存器通信接口為數據通信和共享提供了有效的方法。寄存器通信的時延為7~11個時鐘周期,遠小于DMA (超過25個時鐘周期)和全局存取(超過600個時鐘周期)的開銷。因此,一個通用的方法是將從核LDM中或寄存器中的數據通過寄存器通信發送給其他從核,實現數據共享,減少對全局內存的訪問頻率。
寄存器通信的編程模式給開發者帶來了挑戰。由于實際應用中可能存在復雜的核間通信和同步關系,阻塞式的通信接口會顯著增加程序設計的難度,開發者需要謹慎考慮核間數據傳輸關系,排除死鎖的可能性。由于從核接收緩沖區大小有限,如果發送從核(即發送數據的從核)傳送的數據規模較大,則需要保證目標從核在自身阻塞前能夠完成接收,否則可能出現級聯阻塞現象。另外,在多發送者-單接收者的模式下,可能會存在數據亂序的問題,需要額外考慮程序的正確性。這些都給程序設計和優化帶來了很大難度。
(4)SIMD向量化的使用
單指令多數據流(single instruction multiple data,SIMD)是SW26010的一個擴展的功能模塊。SW26010提供了256位的寄存器,每個寄存器可以存放8個整型數或4個浮點數。使用這些寄存器進行向量化運算,可以達到一條指令得到多個結果的效果。SIMD從源操作數的數組空間將數據裝載到256位SIMD寄存器,并通過SIMD運算指令完成計算,最后將結果存儲到目標操作數的數組空間。SIMD不僅降低了功耗,而且顯著提高了性能,定點和浮點的理論峰值性能為單部件的8倍或4倍。循環展開(loop unwinding)作為一種犧牲程序的尺寸來加快程序的執行速度的優化方法,可以由程序員完成,也可由編譯器自動優化完成。對于擁有多個計算部件的SW26010,SIMD可以被看作一種指令形式的循環展開,SIMD向量化寄存器為多個運算器提供了指令級并行。SW26010編譯器提供了簡潔的SIMD編程指令來顯式地開發指令級并行,開發者不再需要對代碼進行手動展開或依賴編譯器的自動優化。
向量化為申威架構下的程序提供了巨大的性能機遇,但其實際應用存在一些困難。向量化適用于連續型數據訪問和運算,對于非連續型(如AOS類型)數據,其裝載和存儲過程帶來的開銷可能超過計算優化本身帶來的收益。因此,開發者應當注意SIMD使用的可行性,要合理使用向量化,需要時可對數據排布進行調整。
例如,分子動力學應用需要按前文所述的方法將數據轉化為AOS形式的粒子數據包,以最大限度地提升DMA性能。但這種AOS形式的數據并不適合向量化。為此,對于局部獲取的數據,需要進行類似矩陣轉置的轉化,使得相同數組的元素在存儲空間中連續,如圖3所示,將一個粒子包內的數據轉化為每種元素連續的形式,這樣可以用向量寄存器存儲,并開展計算。這種轉換操作可以使用SW26010支持的指令(如simd_vshulff)高效地完成。參考中的一個粒子數據包包含4個粒子的數據,轉換完成后的數據剛好按照4個浮點數對齊,放在一個4浮點數向量寄存器內。
4 大規模稀疏計算問題的性能優化實踐
4.1 高分辨率大氣模擬中的隱式求解
大規模大氣動力模擬對于天氣預報和預測氣象災害有重大意義,該領域的應用往往涉及對大規模網格的計算和求解。此前,國內相關研究實現了基于CPU-GPU和CPU-MIC加速的顯式時步全球淺水波(shallow water)模式,它們分別在天河-1A和天河2號上取得了800 TFlops和1.63 PFlops的性能,擴展到半系統級別。此后,以上工作被擴展到3-D非靜力模式,在天河2號上取得8%的峰值浮點運算效率。然而,這些工作只關注了顯式求解過程,在高分辨率的大氣模擬中,傳統的大氣動力學方程顯式求解方法面臨計算步長過小的問題,因此隱式求解成為可能的解決方法。但隱式求解方法又面臨收斂性和稀疏線性方程組求解低效的問題,如何在隱式求解算法上開發千萬核并行是待解決的問題。
三維非靜力大氣模擬過程主要涉及對完全可壓縮歐拉方程的求解。在超大規模方程組求解中如何保證魯棒性較強的收斂率是一個問題,為此,淺層區域分解多重網格(domain decomposition-multigrid, DD-MG)算法被提出。圖4展示了一個3層的DD-MG算法,在每個k-cycle的MG層級,一層RAS方法被作為區域分解的預條件,從而在處理器層級最大限度地開發并行性。DD-MG算法保證了求解過程的收斂性,同時,作為一種粗粒度的并行,其保證了核組間的負載均衡。
大規模隱式方程求解的性能取決于局部求解的性能,為此,參考提出并實現了高局部性、細粒度和無同步的本地求解器。對于指定的重疊子區域,基于低秩的7點空間偏導構建近似的雅可比矩陣,并在每個網格點中對未知數進行排序。該過程不破壞原有矩陣物理成分的聯系。在DD-MG的框架下,可以用不完全LU(incomplete LU,ILU)分解方法對子區域開展求解。傳統的LU分解由于矩陣非零元的相互依賴和可能的不規則分布,很難有效通過并行算法進行求解。為此,在適用于眾核架構的并行ILU(parallel incomplete LU,PILU)方法的基礎上進行改進,幾何流水化ILU(geometrybased pipelined incomplete LU,GPILU)算法被提出,這種方法在保持數據依賴關系的基礎上很大程度地開發了片上并行性。
在整體算法實現上,參考文獻在處理器、線程及指令層級上開展了不同程度的優化,在隱式求解器的關鍵運算核心上取得了有效的性能提升。
考慮到SW26010的特性,參考針對不同計算核心提出了3種不同的劃分策略,如圖5所示。這里假設主存內的三維AOS數據按照z-x-y的維度順序存儲, core(i,j)表示處理器陣列中第i行第j列的從核。右端相關運算核心中,相應的模板計算有13個依賴點,整個求解區域被分為內部區域(inner)和halo區,halo區是不同節點計算區域的鄰接部分,由頂部、底部和東西南北6個面組成,這些部分都涉及數據通信。不需要通信的內部區域采用2.5D分塊與雙緩沖策略結合的方法,如圖5(a)所示,分塊大小由LDM大小、向量化程度、雙緩沖占用率和DMA效率綜合考慮決定,最終采用4×4的大小。MAT運算核心沒有halo區,因此沿軸按“柱”方向進行1D分塊,如圖5(b)所示。這里的分塊大小應當是4的倍數,以方便向量化。ILU核心實現了線程間和線程內部的并行,分塊方式如圖5(c)所示。在xy平面上,分塊把整個求解區域劃分成8×8的子區域,每個子區域中沿z軸的一“柱”剛好對應8×8=64個SW26010處理器眾核。在這種粒度的劃分下,求解流水線開始/結束時從核間的負載不均衡可以被最小化,水平和豎直方向上的兩層流水線可以高效地工作。類似地,前代/回代過程(下三角/上三角矩陣求解)采取類似的劃分方法。
在2.5D分塊中,每個從核對內存的訪問存在一定間隔,導致內存帶寬的不充分利用。一種利用寄存器通信的在線數據共享方法可以有效解決該問題。如圖6所示,該方法將4個從核分為一組,通過3個步驟完成數據共享,在第一步分解操作中,對于求解的內部區域,組內的從核從內存讀入計算區域和兩層halo區,共4×4+2×2=20個元素的數據;在第二步復制操作中,每個核上對應的數據區域被擴展,開辟冗余的halo區,從而形成4×(4+2×2)=32個元素區域;在第三步交換操作中通過快速的寄存器通信在從核間傳遞計算所需數據,這種數據交換不涉及LDM與內存的數據傳輸,減輕了內存帶寬的負擔。圖6中的4個從核通過3個步驟完成數據交換,每一步之后都需要進行同步。一般來說,增加每組包含的從核個數可以顯著地提升數據重用效率,但相應的同步開銷會增大。實驗表明, 4個從核分為一組最好地平衡了兩者。
為了更好地實現向量化,參考中實現了高效的AOS和SOA轉換接口。這里使用SW26010的shuffle指令,可以在十幾個時鐘周期內將結構內的AOS數據裝載到256位向量寄存器中。另外,部分數據操作(如BLAS-1向量更新和halo區交換)需要在SW26010上得到實現和優化。基于申威架構的xMath數學運算加速庫是為了高性能數學運算開發的,提供了BLAS、LAPACK和FFT操作接口。調用該庫并添加一些手動優化,可以在BLAS-1向量操作上取得20倍以上的加速。
以上提及的完全隱式方程求解器應用已被成功地擴展到整個“神威·太湖之光”超級計算機的超過100萬個的異構眾核上,在雙精度求解下性能達到了7.95 PFlops。實驗中,在488 m水平分辨率(超過7 700億個非零元)條件下,該應用依然能夠實現快速而精確的大氣模擬,成為世界上較大規模的完全隱式模擬之一。
4.2 非線性大地震模擬中的顯式求解
我國是受地震災害影響嚴重的國家,分布有23條地震帶,7度以上的高烈度區域約占國土面積的50%。對地震的模擬和預測可以有效減少地震災害帶來的損失。很多與地震模擬相關的應用已經開始在大規模并行計算機系統上尋找答案,以開源軟件AWP-ODC(anelastic wave propagation by Olsen,Day and Cui)為例,該軟件自2008年起開始推進在千兆級計算機系統上的應用,2016年該應用完成了對非線性效應模擬的支持,并在“泰坦”超級計算機上取得1.6 PFlops的性能,擴展到半系統級別。
由于計算過程中每個網格點都需要對超過20個變量進行讀寫,傳統的分塊策略并不適用。為此,參考提出了一種自定義的多級計算區域分解策略(如圖7所示),包括MPI分解、CG核組分塊劃分和CPE從核分塊劃分。在LDM空間利用策略的計算過程中,計算區域和完成區域不斷向前推進,未完成區域逐漸縮小,緩沖區域用來存儲計算所需的鄰接區。這里假設主存內的三維AOS數據按照z-x-y的維度順序存儲,該方法先沿著xy平面對求解區域進行2D劃分,并分配到每個MPI進程中。這是由于在該應用中豎直(z軸)方向的長度要遠小于水平(x軸和y軸)方向的長度,這種劃分方法可以有效減少MPI進程間的通信量。第二層沿著zy平面進行塊劃分,并將該層的每個塊分配給一個核組。最終,第三層依然沿著zy平面把核組中的塊劃分成數個不同的區域,將每個區域分配給一個SW26010處理器從核,每個從核線程沿著x軸方向開展迭代,從而確保快速訪問內存。考慮到每個LDM空間大小有限,每個從核一次通過DMA載入適當大小的計算區域,包括內部計算區域和halo區。隨著計算的進行,從核緩存區域會沿x軸方向向后推進。DMA被設置為異步的,以達到與計算重疊的效果。這里各層級的分塊大小可以根據問題規模、LDM空間大小及單個網格點的變量數目等因素動態計算得出,實際應用中采取計算分析得到的最優值。
為了在同樣的內存帶寬和存儲空間大小的限制條件下取得更高的性能,參考文獻還提出一種有損壓縮策略,有效解決了在線壓縮和解壓縮開銷與整體應用有效性能提升的矛盾,也有效保證了應用的工程計算精度。如圖8所示,每個參與計算的從核(CPE)先從主核內存,也就是主存中通過DMA讀操作(dma_get)將壓縮后的16位數據讀入LDM,并解壓縮為32位數據,然后進行32位數據上的實際計算,并將計算結果重新由32位壓縮為16位的數據,通過DMA寫操作(dma_put)存入內存。
圖9展示了3種不同的有損壓縮方法,其中用sign exp表示指數,frac表示尾數。計算所用數據在壓縮前固定為32位浮點數,壓縮后的16位數據可以采取不同的表示方法。方法1進行IEEE 754標準32位到16位浮點數的轉化,直接將壓縮后的數據定義為IEEE 754標準的半精度浮點數,包含固定的5位指數和10位尾數。編譯器內置的對半精度浮點數的支持使得壓縮前后的數據轉換效率很高,但由于指數位數少,數值分布范圍較大的變量可能出現溢出,進而引入數值精度問題。而對于數值分布范圍很小的變量而言,5位的指數可能是一種浪費。針對這一問題,方法2使用動態方法定義指數位數。對于每個參與計算的變量,計算其一定范圍內的數值范圍分布,并根據范圍動態分配不同變量壓縮后的指數位數,在保證能覆蓋大范圍指數分布的同時,也能為小范圍數值分布的變量保留更多的尾數位數。但這一方法的轉換效率和計算效率較低。方法3被用于模擬程序速度和壓力變量的壓縮,它將數組中的元素規格化到1和2之間,并采用16位定點小數的表示方法。這種方法平衡了性能和精度,因此在實際應用中具有最好的效果。在地震波傳播核心部分采用有損壓縮策略,最終能取得約24%的性能提升。
該地震模擬應用經過以上優化,可以在“神威·太湖之光”超級計算機上達到超過15%的系統峰值性能,超過了類似應用在“泰坦”超級計算機上的表現(11.8%),且其具有強可擴展性,幾乎可以線性擴展到全機上千萬核。在18 H z、8 m分辨率的超大規模地震模擬中,該應用可以達到18.9 PLlops的持續性能。
4.3 “神圖”圖計算框架
圖是數值科學領域應用頻繁的概念之一,隨著大數據處理問題規模的增大,圖數據結構的大小也相應增大,需要高效可擴展的圖處理系統來解決圖計算問題。比如,人類基因研究目前需要對擁有超過50億個點/邊的布魯因圖(de Bruijn graph)進行處理,類似地,人腦建模分析要考慮超過1 000億個神經元以及每個神經元的平均7 000個突觸連接。圖計算是典型的大數據稀疏處理類問題,浮點運算少,訪存隨機性大,對數據存儲和管理提出了很高要求。同時,冪律分布造成通信和計算負載不均衡,對于復雜圖而言,計算過程中存在大量的核間和節點間通信,通信次數多,通信量少,非常低效,給系統的效率和可擴展性提出了巨大挑戰。
“神圖”是首個運用千兆級系統解決百萬規模圖處理問題的通用框架。
針對申威處理器的異構特性,“神圖”在不同層級對硬件功能進行劃分。在粗粒度的層級上,每4個核組被分為一個節點,分別具備4種不同的功能:一是生成,讀入當前組分配的節點數據,識別待處理圖中的“活躍”點,并生成通信消息;二是轉發,路由聚合后的消息,提供高吞吐率的組間通信;三是粗排序,實行第一階段的初步桶排序,每個桶可以適應性地放入從核LDM中,為下一階段做準備;四是更新,圖處理過程的最后一步,對每個桶進行排序,并更新目標節點。
“神圖”引入了超節點和處理器上的兩級路由機制與高效的專用數據排序策略。超節點路由方法解決了小型消息過多及通信節點對過多帶來的通信開銷問題。“神圖”將數個節點劃分為一個組,數個組屬于一個超級節點。每個節點將屬于相同目標組的通信消息聚合為一條,發送給相應組內的一個節點。該節點中負責轉發的核組會將消息解包并發送給其他核組。圖10展示了超節點多級路由的工作過程,超節點中的一組包含4個核組,超節點X中A節點作為生成節點,發送消息給超節點Y中的排序和更新節點C,中途通過超節點Y中的轉發節點B進行轉發。
大部分圖計算應用受限于內存帶寬,細粒度的隨機內存訪問會對性能造成影響。為此,“神圖”提出了一種片上排序的方法。圖10中節點C可能會按隨機順序接收圖中節點更新的消息,片上排序把更新消息的不同目標點進行劃分和排序,同時合并對相同目標點進行更新的消息,顯著減少了內存總線負載和同步開銷。如圖11所示,每個用于排序的核組中的眾核又被分為3類:p為消費者,負責讀入數據;r為路由者,負責傳遞數據;c為消費者,負責使用數據進行計算,剩下的從核被用于其他任務。初始輸入是無序輸入,經過兩步片上洗牌操作,數據變為有序,可開展后續處理。核組3完成第一階段的初步桶排序操作,把數據放在不同的桶中,使數據成為半有序狀態,核組4利用其結果完成對整個數據的排序。
在真實應用的圖中,點的入度/出度往往呈現指數級增長。在分布式圖處理系統中,度數高的點會產生大量的數據通信,涉及系統中的大部分節點,給通信網絡帶來巨大負載。“神圖”將這種度數高的點復制到每一個計算節點中,原本負責該點的計算節點存儲的是原件,其他計算節點存儲的是鏡像。高出度的點需要向外發送的消息很多,為了避免大規模地發送更新消息,每一個計算節點通過簡單的MPI_Bcast接口協作更新所有鏡像,再根據鏡像來更新其對本地點的影響。對于高入度的點,“神圖”采用類似的方法,計算節點先對本地鏡像進行更新,最后使用MPI_Gather或MPI_Reduce接口更新原件。這種與節點度相關的通信優化模式顯著減少了通信量,減輕了并行系統互聯網絡的壓力;同時,鏡像的存在將高度數點的處理工作平均分配給每一個計算節點,均衡了系統負載。
“神圖”圖計算框架可在分鐘級完成對搜狗中文網頁圖的處理,每次迭代僅需8.5 s,解決了過去由于機器規模和計算框架限制而無法解決的問題。
5 結束語
目前超算發展進入E級階段,新的超大規模異構并行計算機在解決富有挑戰性的計算問題方面的潛力是值得期待的。異構眾核并行系統的設計已經成為高端超算系統的重要構建方式。但其給大規模稀疏處理問題帶來了挑戰。稀疏問題具有非規則的計算與訪存特征,對并行應用的存儲管理、負載均衡、數據通信等提出了更高的要求,需要開發者依據軟硬件特點開展設計和優化,兼顧性能、成本、功耗等多方面的約束。異構眾核系統的架構設計具有巨大的性能潛力,但也給應用實現和優化帶來更高的難度。本文總結了基于“神威·太湖之光”超級計算機的大規模隱式/顯式求解器和“神圖”圖計算框架的性能優化經驗,涵蓋任務劃分、存儲訪問、數據壓縮、數據共享與通信等多方面,為新一代異構眾核計算系統的稀疏問題求解提供了借鑒。實際上,基于異構眾核架構的大規模計算問題的求解和優化案例還有很多,在應用和算法設計層面,動態稀疏問題的高效求解算法設計依然是急需解決的問題。同時,許多實際科學與工程問題中的大規模應用性能優化方法還期待著更多的開發者投入研究。
聯系我們:
Tel:010-81055448
010-81055490
010-81055534
E-mail:bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
轉載、合作:010-81055537
大數據期刊
《大數據(Big Data Research,BDR)》雙月刊是由中華人民共和國工業和信息化部主管,人民郵電出版社主辦,中國計算機學會大數據專家委員會學術指導,北京信通傳媒有限責任公司出版的期刊,已成功入選中文科技核心期刊、中國計算機學會會刊、中國計算機學會推薦中文科技期刊,并被評為2018年國家哲學社會科學文獻中心學術期刊數據庫“綜合性人文社會科學”學科最受歡迎期刊。
關注《大數據》期刊微信公眾號,獲取更多內容

丁楠明