
科技改變生活 · 科技引領未來
科技改變生活 · 科技引領未來

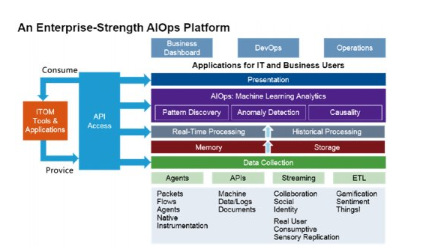
傳統運維管理的人工及被動響應方式,已經無法支撐數字化業務靈活、快速的發展,要靠智能運維(AIOps)能力來獲得數據分析和決策支持。而從傳統ITOM到智能運維的演進過程中,需要一系列關鍵技術的支撐。本文試圖就智能運維落地過程所需關鍵技術點進行概要說明。
智能運維AIOps關鍵技術概覽
從智能運維的平臺架構來看,可抽象為幾個層面:數據采集層、數據匯聚層、數據存儲層、建模應用層、分析學習層、應用反饋層。這是一個非常理想的層次劃分,但在智能運維實踐落地過程中,卻存在著諸多坑壑,需要我們正視和解決。
數據采集與傳輸
運維數據的產生和采集來自于ITOM監控工具集,通常包括:基礎服務可用性和性能監控、網絡性能監測與診斷、中間件服務可用性和性能監控、應用性能管理、系統運行日志管理、IT資產管理、IT服務支持管理等。
這些基礎監控工具采集的運行狀態數據和運行性能數據,需要具備足夠存量的數據和數據增量;以及足夠的數據維度覆蓋度(時間維度、空間維度、系統級維度、應用級維度等)才能進行建模利用。與此同時,運維數據的時效性強、多維數據源割裂采集的現狀、以及如何在后續建模過程中進行多維數據的高效關聯,因此智能運維平臺對數據采集層提出以下技術要求:
·跨平臺、跨語言棧、高兼容性的多模式統一采集質量標準;
·兼容多種非容器化與容器化運行環境;
·一致的維度關聯屬性;
·在資源占用、數據壓縮比、時效性之間可權衡、可調節的傳送機制;
·可靠的熔斷和止損機制;
·易于部署和維護、統一的配置和任務管理。
數據匯聚、存儲與建模
數據的增量是迅猛的,或將達到網絡的上行極限或磁盤的寫入極限,因此對匯聚層的服務自身可用性和吞吐性能要求極高。匯聚層更像“數據湖”,提供元數據限制更為寬松的數據寫入和獲取途徑、簡易的數據清洗任務創建與管理、靈活的數據訪問控制和使用行為審計、具備從原始數據的發掘中更便利的進行價值發掘、具備更敏捷的擴展特性等。
同時,在設計匯聚存儲層的建設方案時,需要避免數據泥沼、無法自助建模、無法執行權限管控等困境。在智能運維實踐落地時,要由一組大數據業務專家/架構師,明確地為匯聚與存儲層設計一系列的能力項,這些能力項不僅要滿足“數據湖”的諸多特征,還要具備便捷的開發和實施友好性,降低數據接入與抽取清洗的成本,它應該具備至少以下關鍵技術能力:
·多數據源、海量數據的快速接入能力;
·元數據提取和管理能力;
·極其簡易的、高性能的數據清洗轉換能力;
·可根據數據字典或特征算法對數據進行關鍵字識別、模式識別的標記能力;
·自動的、自助的,對敏感數據進行脫敏或加密處理能力;
·對數據質量檢驗并對質量標準進行歸一化處置的能力;
·數據可依據某種維度或特征進行所屬和應用權限控制的能力;
·自動的、自助的,數據建模探索能力;
·對已建立的搜索、過濾、關聯、探索模型,友好的進行數據輸出能力;
·自動的、自助的,分布式集群伸縮能力;
·對外提供高效、敏捷數據服務的能力。
智能運維AIOps關鍵技術概覽
云智慧專業運維數據庫DODB(Digital Operation Database)正是符合上述設計目標的一款專業運維數據庫,基礎運行環境搭建在CDH/HDP之上,包含了HDFS、Kafka集群、Zookeeper集群以及Spark集群。
DODB可方便地進行采集任務的配置和管理,支持數百種數據源,包括日志數據采集、數據庫和中間件數據性能數據采集、數十種數據庫中表數據采集、數十種數據消息中間件中數據采集等,支持集群部署、中心化配置管理、狀態自監控與高效熔斷等能力,支持高可擴展性,同時巧妙的解決了數據泥沼和無法自助建模的困擾。
算法體系建設
在智能運維(AIOps)落地實踐中,算法體系的建設是至關重要的一個環節。算法體系建設方面,應從三個角度來去考慮實現思路:
·感知:如異常檢測、趨勢預測、問題定位、智能告警;
·決策:如彈性擴縮容策略、告警策略;
·執行:如擴縮容執行、資源調度執行。
智能分析系統將感知、決策、執行三個角度落地到智能運維解決方案中,形成發現問題、產生告警事件、算法模式定位問題、根據分析結果解決問題的閉環功能。
因此,智能分析平臺應具備交互式建模功能、算法庫、樣本庫、數據準備、可擴展的底層框架支持、數據分析探索、模型評估、參數及算法搜索、場景模型、實驗報告、模型的版本管理、模型部署應用等功能或模塊。
云智慧智能分析平臺DOIA(Digital Operation Intelligent Analysis),依托DODB專業運維數據庫提供的基礎大數據資源,賦予智能運維的能力,包括動態基線、異常檢測、根因分析、智能合并、智能故障預測、知識工程等。智能分析平臺是產出算法,滿足跨平臺、多樣化的客戶現場環境,從最小單元化部署到大規模集群式部署的可行性方案。
算法和數據的工程融合
在智能運維(AIOps)平臺落地的實踐中,算法和數據的融合,第一步是數據的采集和匯聚,通過前文介紹的關鍵技術,我們已經獲得了質量標準歸一化的、經過了提取和轉換的、時間/空間/業務維度標記清楚的數據,需要補充的是數據預處理相關的核心要點。
1、數據預處理
在數據挖掘中,海量原始數據中存在大量不完整(有缺失值)、不一致或有異常的數據,嚴重影響到數據挖掘建模的執行效率,甚至可能導致挖掘結果的偏差。數據預處理的目的是提高數據質量,從而提升數據挖掘的質量。方法包括數據清洗、數據集成和轉換,以及數據歸約。
通過數據預處理,可以去掉數據中的噪音,糾正不一致;數據集成將數據由多個源合并成一致的數據存儲,如數據倉儲或數據立方;數據變換(如規范化)也可以使用,例如規范化可以改進涉及距離度量的挖掘算法的精度和有效性;數據規約可以通過合并、刪除冗余特征或聚類來壓縮數據。這些數據處理技術在數據挖掘之前使用,可以大大提高數據挖掘模式的質量,降低實際挖掘所需要的時間。
需要注意,有些算法對異常值非常敏感。任何依賴均值/方差的算法都對離群值敏感,因為這些統計量受極值的影響極大。另一方面,一些算法對離群點具有更強的魯棒性。數據分析中的描述性統計分析認為:當我們面對大量信息的時候,經常會出現數據越多,事實越模糊的情況,因此我們需要對數據進行簡化,描述統計學就是用幾個關鍵的數字來描述數據集的整體情況。
2、算法工程集成
在智能運維(AIOps)算法分析系統中,不同算法對應不同的適配場景,需要根據數據特征模式來選擇合適的算法應用。如指標異常算法的應用:針對周期穩定性數據,我們采取動態極限的模型;針對周期不不穩定的數據,采?頻域分析的模型;針對穩定性的數據采?極限閾值判斷的模型。通過模型選擇的算法,對不同的數據的模型進行適配,達到最優的效果。
因此,想要以開箱即用的方式、采用某種標準的機器學習算法直接應用,而不考慮業務特征,通常并不可行。
我們需要首先考慮該組業務指標間的關聯性,如果有應用或系統間的調用鏈或調用拓撲供參考,這是最好不過的。如果沒有調用鏈或拓撲,則需要先根據已知可能的業務相關性,進行曲線波動關聯、回歸分析等算法分析,獲得極限閾值嘗試得到因果匹配,通過一系列的事件歸集得到相關性,再對每一次反饋進行適應,嘗試自動匹配更為準確的算法和參數,才可能達到期望的異常檢測目標。
智能運維的工程化過程,是一個算法、算力與數據相結合,平臺自身與業務系統反饋相結合的復雜過程。在與業務場景結合的前提下,靈活的算力組織、高效的數據同步、可插拔的服務化、模型應用過程中的高精度與高速度,是AI工程化本身的核心訴求。
總結和展望
智能運維(AIOps)落地的過程中的坑非常多,這是云智慧過去幾年大量行業實踐得到的真實體驗。它對數據平臺搭建、數據采集與傳輸、數據匯聚、存儲與建模、數據計算、AI體系化、場景與工程化融合等方面提出了極其苛刻的要求,需要更專業的、更高質量標準的運維數據庫,還需要一支強有力的分析、架構和開發團隊支撐,才能真正帶來生產力的提高。(作者:高馳濤)

劉夕華